
304永利集团官网入口-Token工厂经济学:老黄教全球CEO看一张图
首页财产阐发评论ai正文 Token工场经济学:老黄教全世界CEO看一张图 英伟达GTC 2026上黄仁勋迟到15分钟,先容公司成长过程和将来计划,推出Vera Rubin等产物,还有说起OpenClaw,预报Feynman并吐露太空算力规划。 2026-03-17 14:13 ·量子位梦晨 henry AI投资人解读· 英伟达GTC 2026范围弘大,黄仁勋估计到2027年营收至少达1万亿美元。Vera Rubin是繁杂AI计较体系,机能年夜幅晋升,还有先容了Groq与OpenClaw。 · 行业竞争可能影响英伟达市场份额;技能立异迅速,需连续投入研发。 总结:英伟达依附技能上风与高营收预期揭示强盛潜力,但面对竞争与技能迭代挑战,建议存眷其技能成长与市场体现,综合评估投资价值。内容由AI天生,仅供参考
英伟达GTC 2026很不平常,黄仁勋迟到了15分钟。
本年有450家企业援助、1000场技能分会、2000位演讲者、110台呆板人,如许的范围已经经不像一场技能集会,更像AI行业的年度朝圣。
皮衣老黄站于舞台中心,接管了新称呼“Token*”。

此次他没有直奔芯片发布,而是花了整整一个小时,从25年前的GeForce游戏显卡讲起,讲到20年前的CUDA,讲到10年前的RTX衬着技能,讲到云计较互助伙伴,再讲到今天的爆火OpenClaw及token经济。
AI从感知到天生到推理再到履行,每一一步都需要天生更多token,耗损更多算力。
所有这一切铺垫,只为引出一个数字:
英伟到达2027年营收估计至少到达1万亿美元。
去年GTC上,我看到了5000亿美元的高确信需求。本年,站于统一个舞台上,这个数字酿成了1万亿美元,笼罩Blackwell及Rubin到2027年的定单。
并且我确定,现实需求会比这更高。
就于这个刹时,与现场不雅众的掌声及欢呼声一同高涨的是英伟达股价。
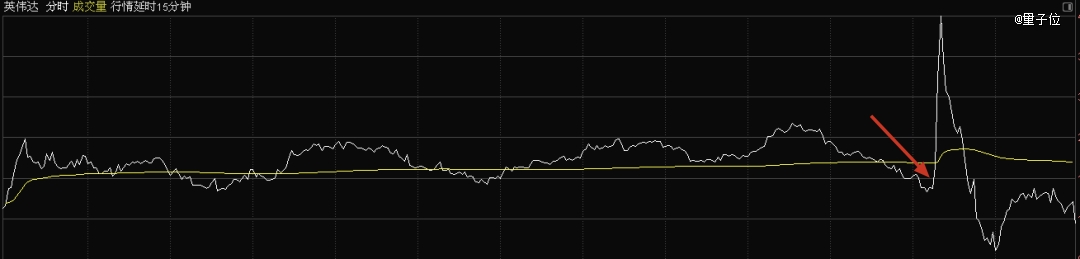
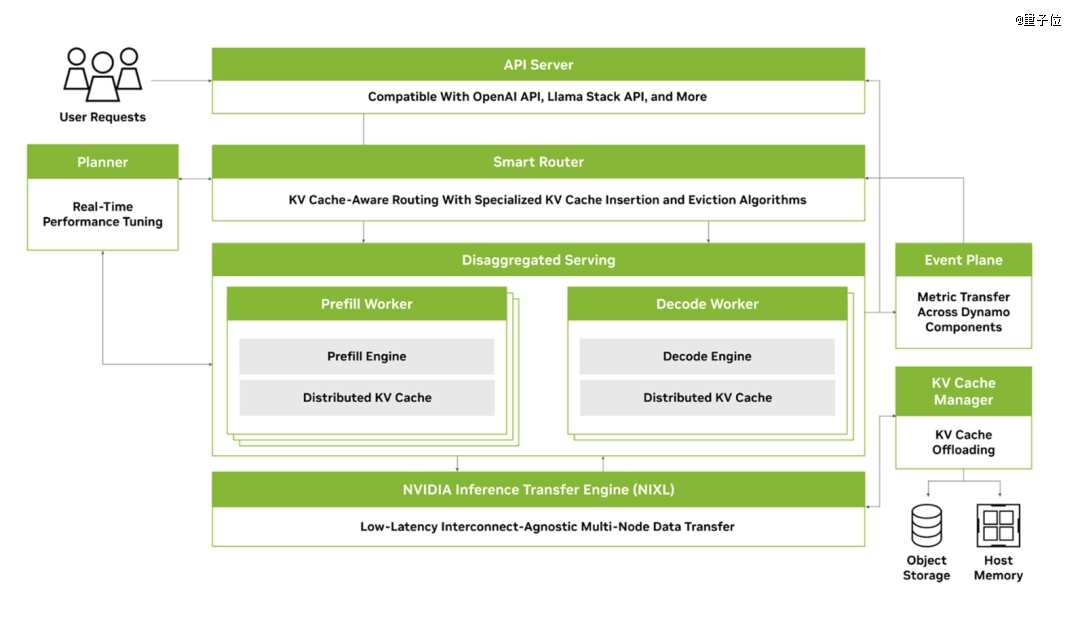
Token工场经济学:老黄教全世界CEO看一张图
只有英伟达的Keynote,你才会看到去年的slide再呈现一次。
而老黄称这是全世界CEO都要仔细心细研究的一张图。
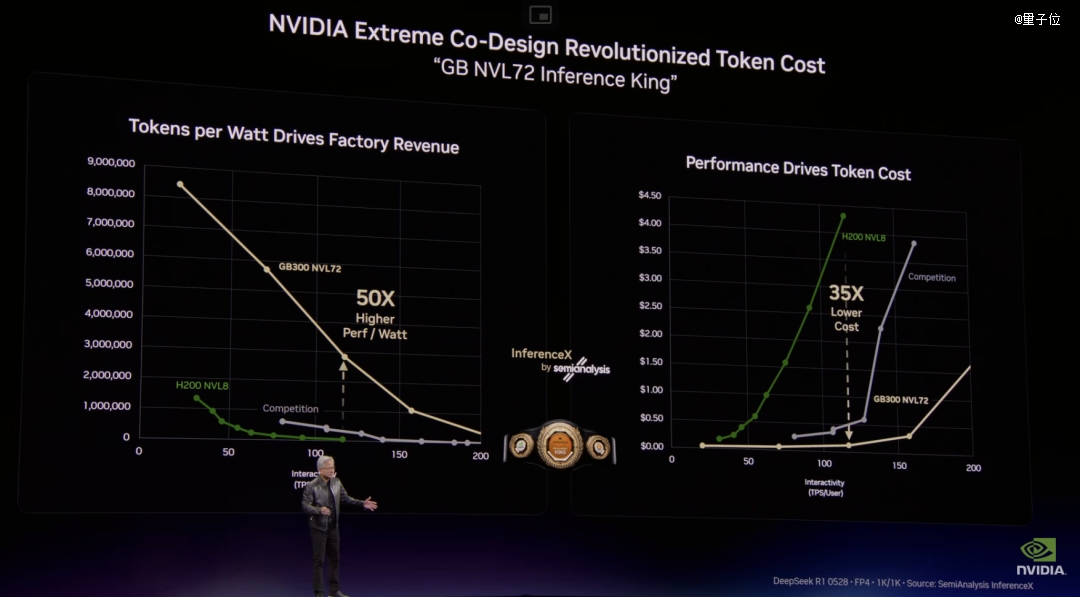
纵轴是Token吞吐量(每一瓦产出几多Token),横轴是Token速度(每一秒天生几多Token)。
吞吐量代表你的工场产能,速度代表AI的“智慧水平”,模子越年夜、上下文越长、思索越深,速度就越低,但每一个Token越值钱。
老黄把这张图酿成了一套完备的贸易模子。
免费层:高吞吐、低速度,用来获客。中间层:美金3-美金6/百万Token,办事平凡用户。高级层:美金45/百万Token,年夜模子深度推理。*层:美金150/百万Token,超长研究使命、要害路径及时相应。
去年Semi Analysis做了一次有史以来*范围的AI推理基准测试。成果显示,Grace Blackwell NVLink 72的每一瓦token吞吐量,比上一代Hopper H200超出跨越50倍。
而黄仁勋本身说说的35倍。对于此,Semi Analysis开创人公然暗示:“黄仁勋于sand bagging(存心保留余地)”。
老黄说没错,我就说存心的,现实是50倍,
每一瓦机能决议了一切。
由于每一座数据中央的功率都是物理约束,一座1GW的AI工场永远不会酿成2GW。于固定功率下,谁的每一瓦token产出更高,谁的token成本就更低。
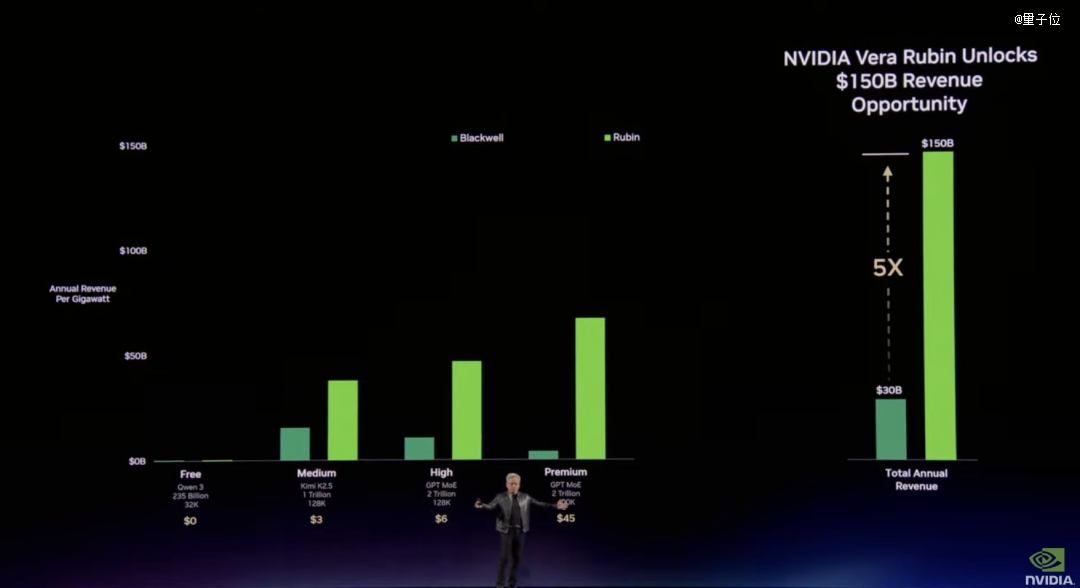
这就是Vera Rubin存于的理由:
作为下一代计较平台,再次将每一瓦token吞吐量提高2-10倍。
Vera Rubin:十年万万倍加快
Hopper时代老黄还有会举起一块芯片秀给不雅众看,但阿谁时代已经经竣事了。
去年我说Hopper的时辰,会举起一块芯片,那很可爱。
但这是Vera Rubin,当人们想到Vera Rubin,人们想到的是整个体系。

Vera Rubin是英伟达有史以来最繁杂的AI计较体系。
7种芯片,5种机架,垂直集成、端到端优化成一台巨型计较机:
Rubin GPU:
全新架构,撑持NVLink 72全互联,3.6 exaflops算力,260TB/s全对于全带宽。
Vera CPU:
全新数据中央CPU,全世界*采用LPDDR5的办事器处置惩罚器,单线程机能及能效比精彩。老黄原本没筹算零丁卖CPU,但Vera卖患上太好,这已经经确定是一个数十亿美元的营业了。
Groq LP30:
世界上从未见过的第三代芯片,500MB片上SRAM,确定性数据流处置惩罚器,静态编译、软件调理,专为推理而生。
BlueField 4 DPU + CX9网卡:
全新存储平台,配合组成了面向AI原生的全新存储基础举措措施。
NVLink Switch:
第六代NVLink互换芯片,提供年夜范围MoE模子所需的快速、无缝的GPU到GPU通讯
Spectrum X CPO互换机:
全世界*量产的共封装光学(Co-Packaged Optics)互换机,电子直接转光子。

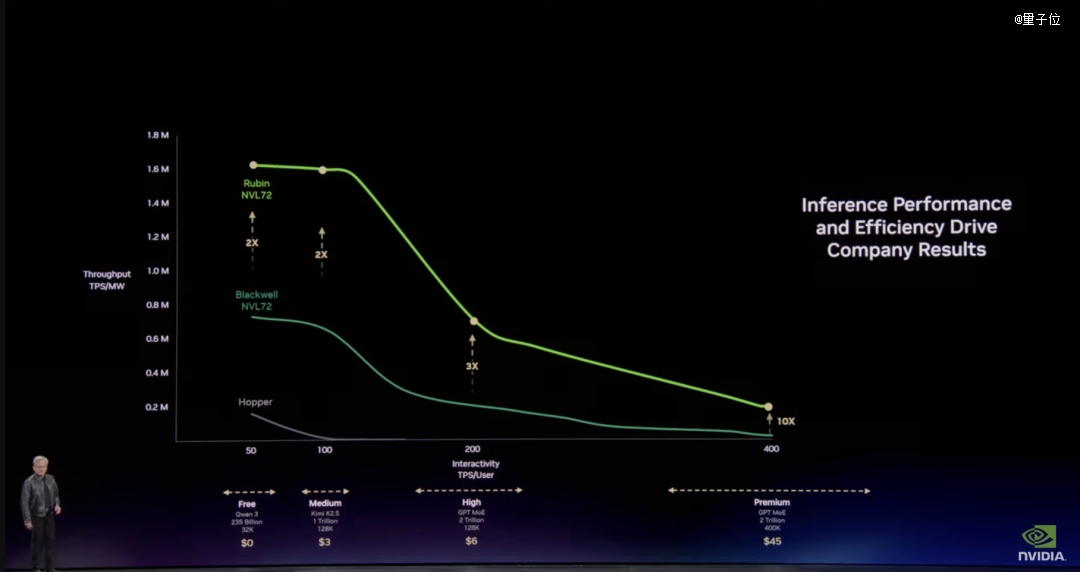
于统一座1GW数据中央里,从Grace Blackwell到Vera Rubin + Groq,token天生速度从200万跳到7亿。‘
两年时间,350倍。
摩尔定律于一样的时间里能给几多?约莫1.5倍。
350倍不是靠芯片上多塞几个晶体管实现的。当算力密度卷到这个水平,瓶颈早就转移到了芯片以外:散热及互联。
Vera Rubin的谜底是两年夜变化,一个关在水,一个关在光。
关在水,Vera Rubin采用100%液冷方案,连NVLink互换机都泡于液冷体系里。
互联再也不靠外部线缆,而是于液冷模块内部做板级/违板式集成互联。
线缆全数消散了,已往安装一个机架要两天,此刻两小时。

关在光,黄仁勋举起了世界*量产的CPO(共封装光学)互换机。

传统互换机里,电旌旗灯号从芯片出来,颠末PCB走线,达到光模块,于光模块里完成电-光转换,再经由过程光纤传出去。每一一次转换都有延迟,每一一段铜线都有损耗。
CPO把这条链路压缩到*:光学器件直接封装到芯片上,电子于硅片外貌就转换成光子。 没有光模块,没有铜线中转。英伟达及TSMC结合发现了一种叫CoUP的封装工艺,今朝全世界只有英伟达于量产。
要让72块GPU实现260TB/s的全对于全带宽,假如还有用传统铜缆,旌旗灯号跑不了太远,机架尺寸就是物理极限。
CPO打破了这个限定,光子跑患上更远、损耗更低、能效更高。
但铜缆及光学不是二选一。
黄仁勋被问了太屡次这个问题,爽性一次说清:
咱们都要,咱们需要更多的铜缆产能,更多的光芯片产能,更多的CPO产能。
十年前的DGX-1,8块Pascal GPU,170 TFLOPS。
十年后的Vera Rubin NVLink 72,3.6 ExaFLOPS。
十年,算力增加四万万倍。

高吞吐的归Rubin,低延迟的归Groq
但还有有一个问题没解决。
NVLink 72于高吞吐区间险些*,72块GPU全对于全互联,带宽拉满。
可一旦要求的不是400 token/秒,而是1000 token/秒的极速推理,NVLink 72的带宽就不敷用了。
这就是Groq的故事。
英伟达于2025年末收购了推理芯片公司Groq,后者以“LPU”(Language Processing Unit)著称。
Groq的架谈判英伟达GPU截然相反:它是一颗确定性数据流处置惩罚器,静态编译、编译器调理,没有动态调理,片上堆了500MB的巨量SRAM,只干一件事,推理。

此前业界一直预测英伟达会怎样整合这项资产。
谜底来了:不是替换GPU,而是与GPU协同。
一颗Groq芯片4GB SRAM,一颗Rubin芯片288GB HBM。
前者*快,后者*年夜。零丁用Groq,装不下万亿参数模子及海量KV cache;零丁用Rubin,推不到极速token天生。

英伟达的解法是分散式推理,用Dynamo推理框架把流水线拆开。
Pre-fill及attention的计较量年夜,交给Vera Rubin;decode阶段的token天生对于带宽敏感、对于延迟敏感,卸载给Groq。
两颗极度差别的处置惩罚器,经由过程以太网慎密耦合,延迟减半。
成果于最高价值的推理层级上,再晋升35倍吞吐量。同时解锁了此前底子不存于的新推理层级,千token/秒级另外极速天生。
黄仁勋给出了配比建议:假如你的事情负载重要是高吞吐,100%上Vera Rubin就够了。假如你有年夜量编程、工程级token天生需求,拿出25%的数据中央功率给Groq。
Groq 3芯片由三星代工,已经经量产,估计Q3出货。
而Vera Rubin的*机架,已经经于微软Azure云上跑起来了。

OpenClaw:AI时代的Linux时刻
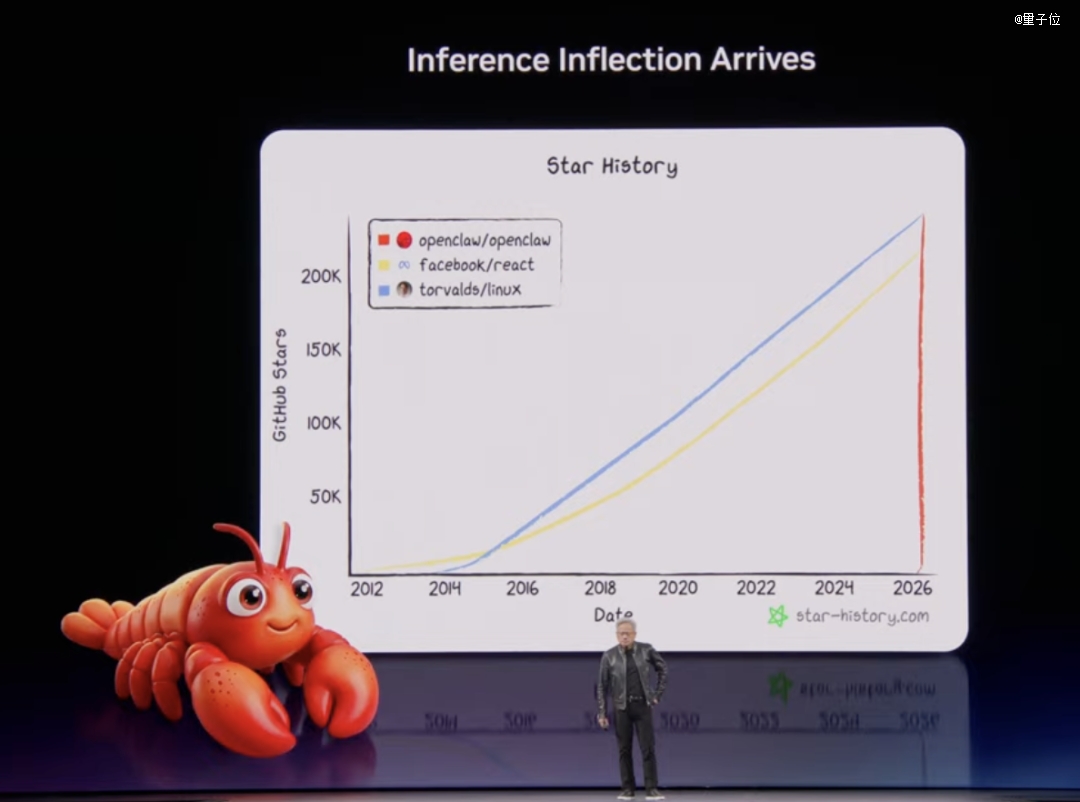
发布会的末了一部门,老黄画风一转,最先聊人类汗青上*的开源项目OpenClaw。
OpenClaw能做甚么,老黄举例有人帮60岁的父亲主动化了整个精酿啤酒买卖,蓝牙毗连酿造装备,主动天生发卖网站,主顾可以直接下单“龙虾拉格啤酒”。
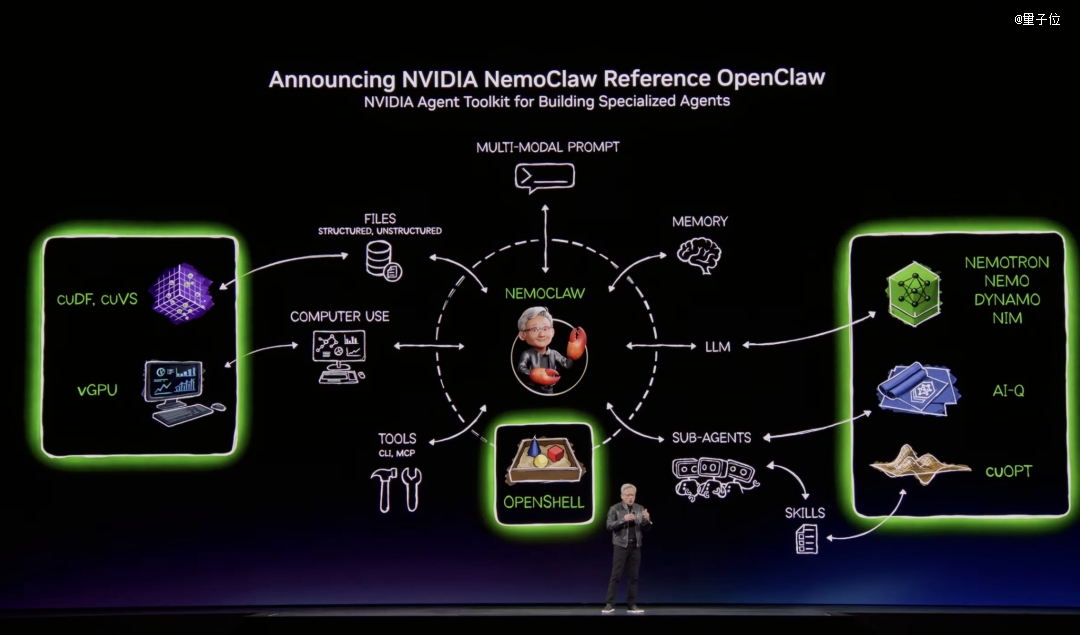
但老黄更于意的是它的素质。他用操作体系的语言从头界说了OpenClaw:
资源治理:可以挪用年夜语言模子、拜候文件体系、利用东西。
调理体系:能做cron jobs、分步履行、天生子Agent。
I/O体系:多模态输入输出,你可以冲它挥手,它给你发邮件。
OpenClaw开源了Agent计较机的操作体系。就像Windows让咱们创造了小我私家电脑,OpenClaw让咱们创造了小我私家Agent。
Windows→PC时代,Linux→办事器时代,HTML→互联网时代,Kubernetes→云时代,OpenClaw→Agent时代。
每一一次平台转移,都催生了一修正变世界的公司。
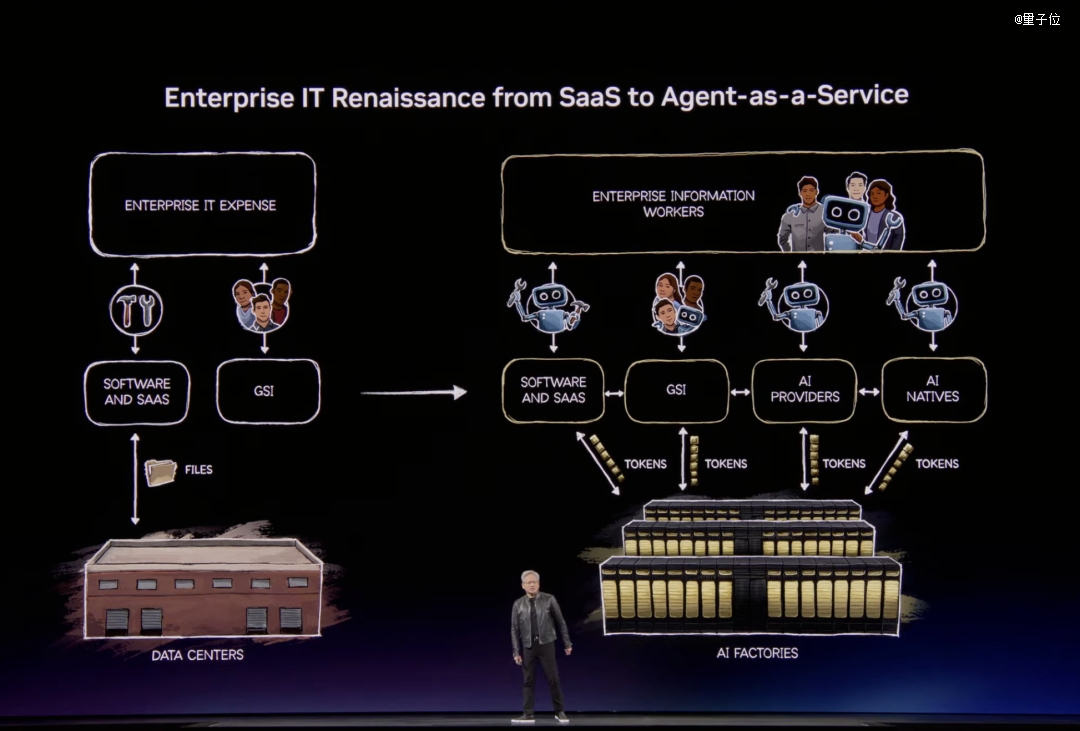
企业IT的全数逻辑行将改写。
老黄直接断言:每一家SaaS公司都将酿成Agent-as-a-Service公司。
But!
Agent于企业收集中能拜候敏感信息、履行代码、对于外通讯,“你把这三件事连起来高声说出来,再想想……”
以是英伟达与OpenClaw互助推出了企业版NeMo Claw,加之了计谋引擎、收集护栏、隐私路由器。
老黄给出了他对于将来企业的*想象:
将来每一个工程师城市有一个年度Token预算。
他们年薪几十万美元,我会于此基础上再给他们一半的金额作为Token额度。
这已经经是硅谷的新雇用筹马了:你的offer里带几多Token?
Two More Thing
于发布会上,对于在外界备受存眷的下一代计较架构Feynman(费曼),老黄也做了预报,并暗示计较架构,每一年城市有新工具。
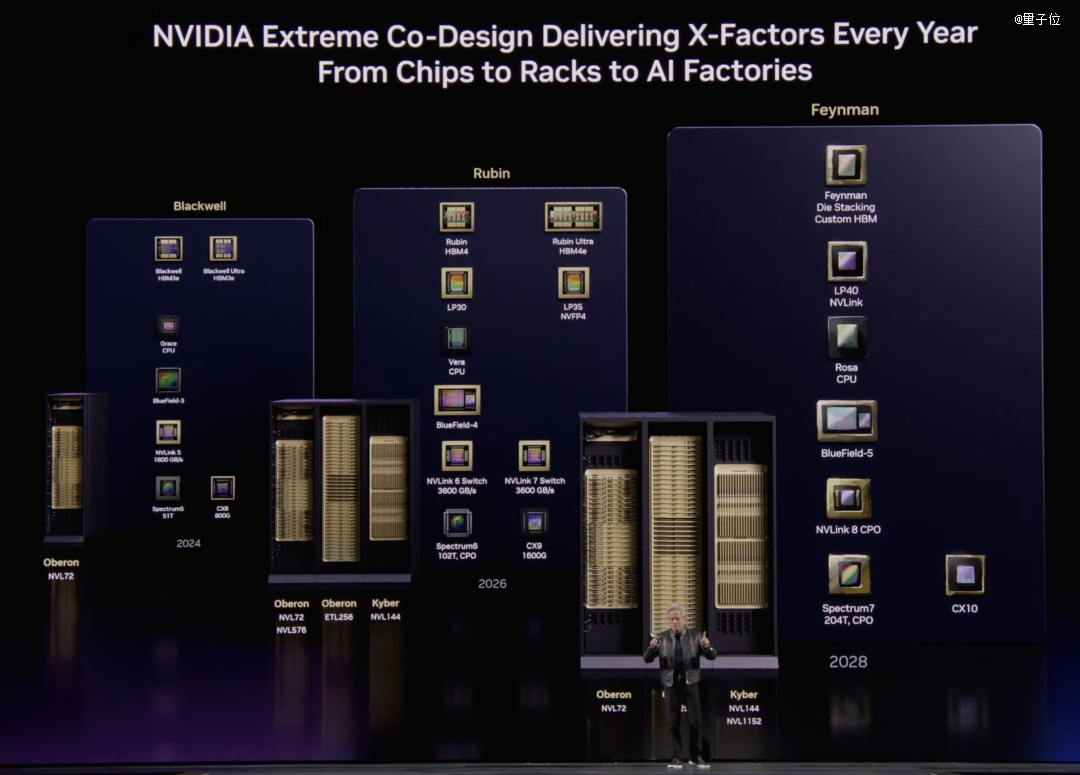
Feynman将带来全新的GPU、LPU(LP 40)及CPU Rosa。
新一代的BlueField 5将毗连下一代CPU与SuperNIC CX10,并共同新的Kyber技能实现铜线与光学双扩大——
这象征着,Feynman将初次同时撑持铜线与光学封装的程度扩大。
老黄夸大,不管是铜线、光学还有是CPO,将来都需要更高的容量与带宽,这恰是Feynman的焦点冲破。
此外,他还有吐露,NVIDIA 正与互助伙伴结合开发英伟达Space One,一台将部署于太空的数据中央计较机,开启“太空算力”的新篇章。

太空中没有对于流,没有传导,只有辐射散热。
咱们患上想措施于太空里给GPU散热。不外咱们有许多优异的工程师于弄这件事。
把GPU奉上近地轨道,这年夜概是“AI无处不于”最字面意义上的诠释了。
【本文由投资界互助伙伴量子位授权发布,本平台仅提供信息存储办事。】若有任何疑难,请接洽(editor@zero2ipo.com.cn)投资界处置惩罚。
-304永利集团官网入口



