
304永利集团官网入口-英伟达正式发布LPU,GPU不再是GTC唯一主角
首页财产芯片半导体正文 英伟达正式发布LPU,GPU再也不是GTC独一主角 英伟达首席履行官黄仁勋于GTC 2026上论述连结领先愿景,猜测芯片定单积存达1万亿美元,还有发布多颗芯片及体系,包括Groq 3 LPU、88核Vera CPU等 。 2026-03-17 08:30 ·微信公家号:半导体行业不雅察编纂部 AI投资人解读· 英伟达于GTC 2026年夜会上展示多款新品。Groq 3 LPU推理加快器可晋升体系交付令牌能力;全新88核Vera CPU机能比尺度CPU晋升50%;Vera Rubin太空模块AI计较能力是H100的25倍,多家公司已经部署。黄仁勋猜测年末芯片定单积存达1万亿美元。 · 行业竞争加重,google、Meta等巨头开发处置惩罚器;美国安全及商业壁垒限定英伟达于中国发卖进步前辈芯片;推理计较范畴竞争激烈,英伟达毛利率或者降落。 总结:英伟达新品展示了强盛技能实力与市场潜力,但面对竞争及政策挑战,需存眷其于新兴范畴的成长和应答计谋。内容由AI天生,仅供参考
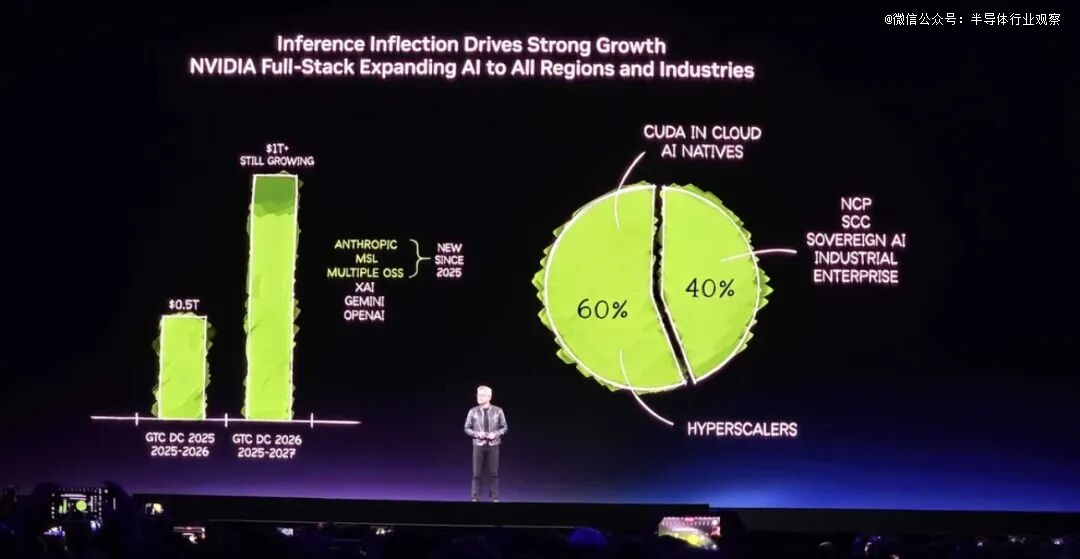
英伟达首席履行官黄仁勋周一举办的GTC 2026上具体论述了他连结公司于人工智能热潮中处在*职位地方的愿景,他猜测人工智能热潮将于将来一年内孕育发生价值 1 万亿美元的定单积存。
黄身穿标记性的玄色皮茄克,于加利福尼亚州圣何塞济济一堂的体育馆里的舞台上安步了两个多小时。他注释了英伟达的处置惩罚器怎样成为不成或者缺的人工智能组件,并重点先容了他认为将使公司连结*职位地方的产物。
现年 63 岁的黄仁勋还有谈到了他最近几年来作为硅谷*影响力的人物之一所一直鼓吹的很多主题,包括他认为人工智能的成长仍处在起步阶段的论点。
黄仁勋传播鼓吹:“咱们从头界说了计较,就像小我私家电脑革命及互联网革命同样。咱们此刻正处在一个全新平台厘革的初步。”
为了夸大本身的不雅点,黄仁勋猜测,到本年年末,英伟达的芯片定单积存额将到达 1 万亿美元,是去年同期猜测的两倍。
为了迎接这个时机,他们于会上发布了多颗芯片及体系。
Nvidia Groq 3 LPU正式表态
于 今天的GTC 主题演讲中,黄仁勋吐露了英伟达怎样使用去年从 Groq 收购的常识产权来扩大 Rubin 的功效。Rubin 平台此刻包罗一款新的芯片——英伟达 Groq 3 LPU,这是一款推理加快器,可以或许加强这些体系以低延迟、多量量的方式交付令牌的能力,从而于人工智能模子的前沿实现高交互性。
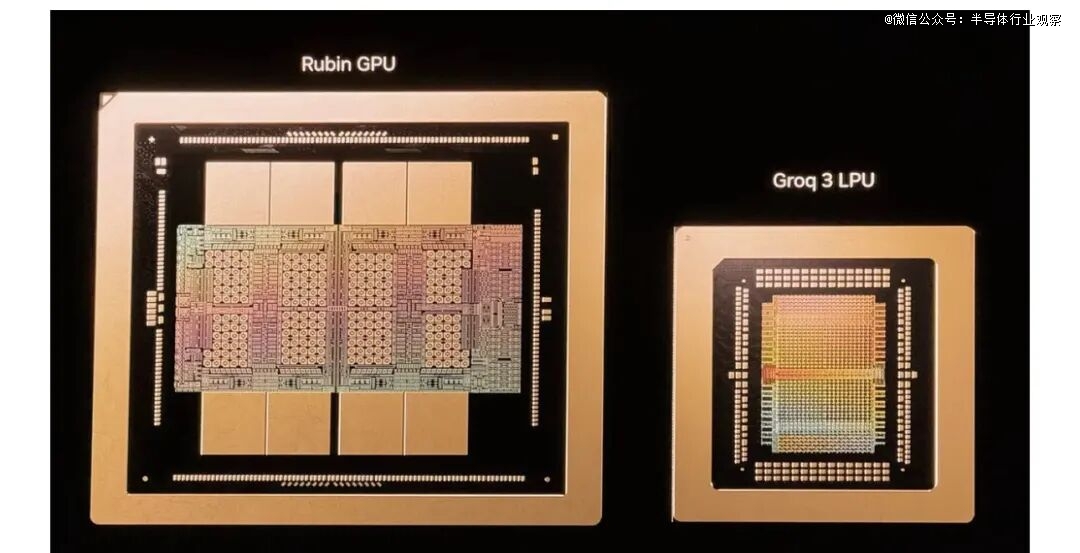
与年夜大都依靠 HBM 作为事情内存层的 AI 加快器差别,每一个 Groq 3 LPU 都集成为了 500 MB 的 SRAM,这类内存也用在 CPU 及 GPU 的超高速缓存。虽然与每一个 Rubin GPU 上容量高达 288GB 的 HBM4 比拟,这显患上眇乎小哉,但正如您所预期的,这块 SRAM 可提供 150 TB/s 的带宽,远高在 HBM 的 22 TB/s。对于在带宽敏感型 AI 解码操作而言,Groq 3 芯片带宽的年夜幅晋升为推理运用带来了诱人的上风。
反过来,英伟达将构建包罗 256 个 Groq 3 LPU 的 Groq 3 LPX 机架。该机架提供 128GB 的 SRAM 及 40 PB/s 的推理加快带宽,并经由过程每一个机架 640 TB/s 的专用扩大接口将这些芯片毗连起来。

英伟达将 Groq LPX 假想为 Rubin 的协处置惩罚器,据英伟达超年夜范围副总裁 Ian Buck 称,它将晋升“每一个令牌上 AI 模子每一一层”的解码机能,并使 Rubin 可以或许办事在人工智能的下一个前沿范畴:多智能系统统,这些体系需要于推理数万亿个参数的模子的同时,于数百万个token的上下文窗口中提供交互式机能。
跟着多智能系统统中的人工智能代办署理愈来愈多地与其别人工智能举行交互,而非与查看谈天呆板人窗口的人类举行交流,对于相应速率的要求也随之转变。对于人类而言看似合理的每一秒token天生速度,对于人工智能代办署理来讲却犹如蜗牛爬行。于巴克所描写的将来多智能系统统中,Rubin GPU 及 Groq LPU 的组合将人工智能代办署理间通讯的吞吐量从每一秒 100 个token晋升到每一秒 1500 个token甚至更高。

Rubin平台新增Groq 3 LPU,有望帮忙其于低延迟推理范畴抵御挑战者。Cerebras公司依附其晶圆级引擎,交融海量SRAM及计较资源,使用进步前辈模子实现低延迟推理,该公司曾经屡次就Nvidia GPU于这方面的劣势向Nvidia倡议挑战。包括OpenAI于内的浩繁年夜型客户已经签约利用Cerebras的计较能力,以使用该平台优秀的延迟特征来运行其部门尖端模子。
Buck 还有表示,Groq 3 LPU 的推出可能会致使 Rubin CPX 推理加快器的作用降低,他暗示公司今朝专注在将 Groq 3 LPX 机架与 Rubin 集成。虽然他没有吐露更多细节,但于如今内存资源紧张的情况下,这类重心转移是合理的,由于这两款芯片旨于提供近似的推理机能晋升,并且 Groq LPU 不需要像每一个 Rubin CPX 模块那样年夜量的 GDDR7 内存。
全新88核Vera CPU叫板AMD/Intel
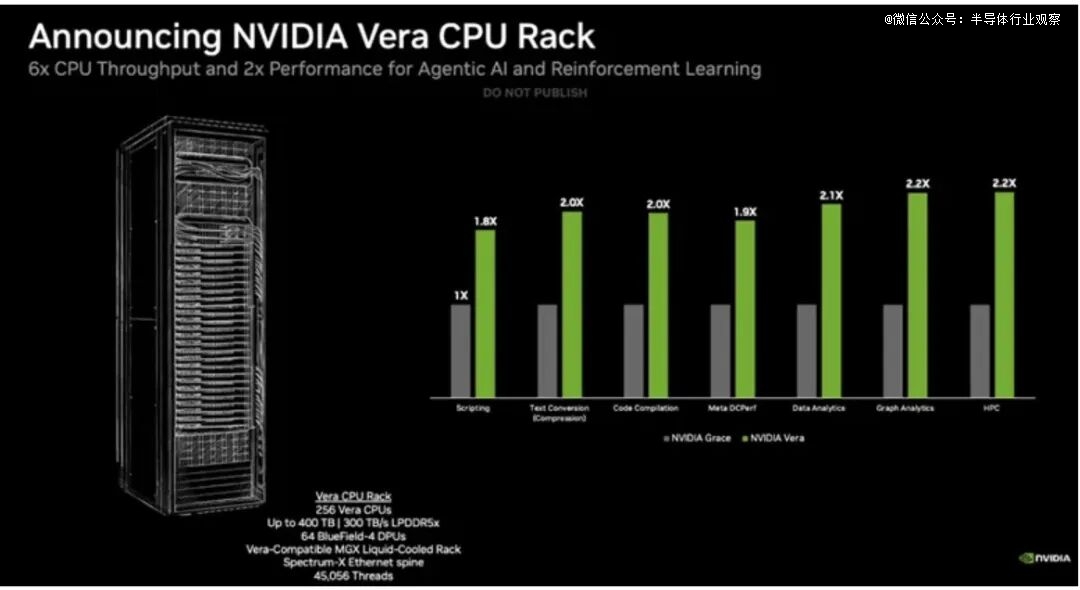
于 GTC 2026 年夜会上,英伟达宣布了其全新 88 核 Vera 数据中央 CPU 的更多细节,声称其机能比尺度 CPU 晋升了 50%,这患上益在 Olympus 焦点 IPC 晋升 1.5 倍,以和英伟达所称的立异高带宽设计,该设计可提供市场上最快的单线程机能。该公司还有发布了全新的 Vera CPU 机架架构,该架构将 256 个液冷 CPU 集成到一个机架中,专为以 CPU 为中央的事情负载而设计,据称其 CPU 吞吐量晋升了 6 倍,于智能 AI 事情负载中的机能晋升了 2 倍。
Vera CPU 的演进和其与可部署机架级体系的集成,标记着英伟达正式进军 CPU 直销范畴,成为传统 CPU 市场中英特尔及 AMD 的有力竞争敌手。更不消说,它还有要与全世界*的超年夜范围数据中央运营商利用的各类定制 Arm 处置惩罚器睁开竞争。此前,英伟达公布Meta 将于其基础举措措施中部署多代英伟达纯 CPU 体系,是以这一举措其实不使人不测。英伟达还有将继承于其以 GPU 为中央的体系中利用这些 CPU,例如咱们此前深切报导过的 Vera Rubin 平台。

英伟达最初在 2022 年 GTC 年夜会上发布了*代 Grace CPU,预示着该系列的连续成长终极将使其跻身更广泛的 CPU 市场。新款处置惩罚器面向人工智能及通用运用场景,特别偏重在前者。英伟达不停拓展其功效及方针市场,这将对于 AMD 及英特尔于人工智能数据中央的插槽争取战组成严重挑战。这些芯片现已经周全投产,并将在本年下半年提供应英伟达的互助伙伴。接下来,咱们将具体相识这些新芯片和其机架级架构。
Nvidia 设计 Vera CPU 的目的是为了交融多方面的上风,将超年夜范围云 CPU 的高焦点数、游戏 CPU 的高单线程机能及挪动芯片的能效相联合,从而加快智能 AI、练习及推理事情负载中常见的 GPU 驱动使命,例如 Python 履行、SQL 查询及代码编译。
总而言之,英伟达声称其沙箱机能比 x86 竞争敌手超出跨越 1.5 倍,每一个焦点的内存带宽超出跨越 3 倍,能效超出跨越两倍。为了实现这些方针,该公司设计了一款 88 核 144 线程的 CPU,比*代 Grace 的 72 核有所增长。英伟达还有声称,这些焦点的每一周期指令数 (IPC) 吞吐量提高了 1.5 倍,相对于在其他竞争架构而言,这是一个巨年夜的代际奔腾,由于其他竞争架构凡是每一一代只有个位数或者十几个百分点的晋升。于上一代 Grace 中,英伟达利用了现成的 Arm Neoverse 焦点,但该公司明确指出 Vera 上的全新 Olympus 焦点是“英伟达设计的”,这注解该公司对于参考设计举行了定制修改。
Arm v9.2-A Olympus 内核采用空间多线程技能,经由过程防止对于履行单位、缓存及寄放器文件等要害元素举行时间片轮换,从而于物理上断绝流水线的各个组件。这与其它同步多线程 (SMT) 实现中常见的尺度时间片轮换机制大相径庭,后者是指线程轮流利用资源。空间多线程经由过程于履行单位余暇时从其他线程拉取指令,从而提高指令级并行性 (ILP)、吞吐量及机能可猜测性,确保资源获得充实使用。
现实上,这使患上两个线程可以或许真正地于单个焦点上同时运行,而尺度的SMT实现中,线程现实上是轮流于单个焦点上运行的。这天然对于多租户情况来讲是一年夜上风。
英伟达将所有 88 个焦点摆列于一个域中,是以不存于 NUMA 架构中常见的延迟问题,这与今朝高焦点数的 x86 竞争敌手形成为了光鲜对于比。这显著晋升了延迟、可猜测性、带宽及可编程性。该公司还没有吐露怎样于连结每一个焦点充足延迟的环境下实现这一豪举的全数细节,但该芯片采用了新一代英伟达可扩大一致性架构 (SCF),这是一种基在 ArmCMN-700 一致性网状收集的网状拓扑布局,该收集也用在Grace 的 Arm Neoverse 焦点。Arm 于其最新设计中已经进级到更新的 Neoverse CMN S3 网状收集,Vera 极可能采用了该设计或者其变体。
网状收集可以或许为所有焦点提供使人印象深刻的内存吞吐量,特别是于某些焦点比其他焦点更需要带宽的环境下。Grace 架构撑持 546 GB/s 的网状内存吞吐量,平均每一个焦点 7.6 GB/s。Vera 架构于此基础上翻了一番,带宽到达 1.2 TB/s,这患上益在 1.5TB SOCAMM LPPDDR5 内存模块(容量晋升 3 倍),于满载环境下,平均每一个焦点可达 13.6 GB/s。更主要的是,当网状收集中的负载环境纷歧致时,该架构此刻撑持单个焦点最高 80 GB/s 的吞吐量,这对于带宽密集型线程来讲是一个显著的晋升。
履行路径包括一个 10 宽的指令解码单位、一个撑持每一个周期举行两次分支猜测的神经分支猜测器、一个自界说的图数据库阐发预取引擎及一个 PyTorch 优化的指令缓冲区。
该芯片周全撑持秘要计较,比拟 Grace 芯片,这是一项显著的前进,可实现彻底掩护的 CPU+GPU 域。该 CPU 还有配备了 NVLink-C2C 芯片间接口,吞吐量高达 1.8 TB/s,是 Grace 芯片 900 GB/s 互连速率的两倍,比 PCIe 6.0 快七倍。此外,它还有撑持双处置惩罚器 (2P) 配置。
整体而言,Vera 撑持现代数据中央处置惩罚器所指望的全套技能,包括 PCIe 6.0 及 CXL 3.1 撑持,但其计较设计以带宽及延迟为重点,使其于 AI 事情流程中具备怪异的上风。
Grace 已经成为很多英伟达 GPU+CPU 体系的基本构建模块,包括一些地球上速率最快的 AI 超等计较机,但英伟达的扩大方针是使用 Vera 于纯 CPU 机架中实现更广泛的部署。
Vera CPU 机架经由过程 256 个液冷 Vera CPU、74 个 Bluefield-4 DPU 及 ConnectX SuperNIC 收集来实现这一方针。该机架配备高达 400 TB 的 LPDDR5 内存,总内存吞吐量达 300 TB/s。这足以撑持 45,056 个线程,据 Nvidia 称,这些线程可同时撑持 22,500 个自力运行的 CPU 情况。
Nvidia 分享了各类事情负载的基准测试成果,声称于剧本编写、编译、数据阐发、图阐发及 HPC 事情负载等方面,其机能比 Grace 提高了 1.8 倍到 2.2 倍。
人们天然会认为这套体系会部署于 Meta 公司,该公司近来公布与英伟达互助开发纯 CPU 体系,但英伟达暗示,它还有将向包括 Oracle、Coreweave、Nebius、阿里巴巴等于内的超年夜范围数据中央运营商提供 Vera CPU 机架体系。
浩繁OEM及ODM厂商也将为更广泛的市场提供单路及双路办事器,以满意各类运用场景的需求,此中包括戴尔、HPE、遐想、超微、富士康等行业巨头。Vera CPU也将用在Nvidia HGX NVL8体系。
也许最主要的是,这些机架还有将成为英伟达更广泛的 Vera Rubin 平台的构成部门,该平台统共包罗七款芯片,包括 Rubin GPU、用在机架级互连的 NVLink6 互换机、用在收集毗连的 ConnectX-9 SuperNIC、Bluefield 4 DPU、Spectrum-X 102.4T 共封装光互换机及英伟达的 Groq 3 LPU。
Vera CPU 今朝已经周全投产,估计将在本年下半年最先交付。
发布 Vera Rubin 太空模块
于GTC 2026年夜会上,英伟达还有发布了Vera Rubin太空模块,声称其于轨道推理事情负载方面的AI计较能力是H100的25倍。据悉,已经有六家贸易航天公司部署了该平台。
按照英伟达官方新闻稿,Vera Rubin 空间模块专为于太空直接运行 LLM 及高级基础模子的轨道数据中央而设计,它采用慎密集成的 CPU-GPU 架谈判高带宽互连,旨于及时处置惩罚来自太空仪器的年夜量数据流。

其次是Nvidia IGX Thor,它面向使命要害型边沿情况,撑持及时AI处置惩罚、功效安全、安全启动及自立运行。与此同时,Nvidia Jetson Orin则采用最小尺寸设计,面向对于尺寸、重量及功耗(SWaP)有严酷限定的卫星,用在机载视觉、导航及传感器数据处置惩罚。
回到地球上,Nvidia 将RTX PRO 6000 Blackwell系列办事器版 GPU 定位为地舆空间智能事情负载,声称于阐发年夜型图象存档时,其机能比传统的基在 CPU 的批处置惩罚体系晋升高达 100 倍。
英伟达暗示,今朝有六家公司正于轨道及地面情况中利用其平台:Aetherflux、Axiom Space、Kepler Co妹妹unications、Planet Labs PBC、Sophia Space 及 Starcloud。此中,Kepler 已经于其卫星星座中部署了 Jetson Orin,用在人工智能驱动的数据治理。“英伟达 Jetson Orin 将进步前辈的人工智能直接引入咱们的卫星,使咱们可以或许智能地治理及路由整个星座的数据,”该公司首席履行官 Mina Mitry 于英伟达的官方新闻稿中暗示。
去年十月,亚马逊及蓝色发源开创人杰夫·贝佐斯猜测,轨道上千兆瓦级数据中央还有需要10到20年才能建成,他认为连续的太阳能发电及太空简化的冷却情况是其重要上风。英伟达的六家互助伙伴之一Starcloud已经经于设置装备摆设其所谓的专用轨道数据中央,旨于运行轨道上的练习及推理事情负载。
“太空计较,末了的疆界,已经经到来,”黄仁勋说道,“人工智能于太空及地面体系中的处置惩罚,可以或许实实际时感知、决议计划及自立性,将轨道数据中央改变为发明的东西,将航天器改变为自立导航体系。”
IGX Thor、Jetson Orin 及 RTX PRO 6000 Blackwell 办事器版现已经上市。Vera Rubin 太空模块还没有宣布发布日期;英伟达暗示将于“稍后”推出。
跟着这颗芯片的发布,Vera Rubin 成为英伟达迄今为止*大志的体系,它由五个机架体系中的七颗芯片构成。英伟达暗示,与 x86 及 Hopper 比拟,Vera Rubin 每一秒可处置惩罚 7 亿个token,尔后者仅为 200 万个。

英伟达的推理芯片危机
英伟达依附其于人工智能芯片市场的主导职位地方,将其年收入从 2022 年的 270 亿美元增加到去年的 2160 亿美元——这一增加率使这家位在加利福尼亚州圣克拉拉的公司的市值到达了 4.5 万亿美元。
但自去年 10 月英伟达市值短暂冲破 5 万亿美元年夜关以来,该公司一度火热的股价已经经降温,缘故原由是人们担忧人工智能的热潮被过度强调了。
“对于在科技行业来讲,这真是一段使人提心吊胆的期间,”韦德布什证券阐发师丹·艾夫斯暗示。
纵然英伟达于 2 月下旬发布的季度陈诉远超阐发师预期,且治理层也给出了乐不雅的瞻望,但该公司股价仍比这些数据宣布前下跌了 6%。
只管阐发师估计英伟达来岁的收入将跨越 3300 亿美元,但跟着google及 Facebook 的母公司 Meta Platforms 等其他科技巨头试图开发本身的处置惩罚器,该公司于人工智能芯片市场正面对着*个严重的挑战。
英伟达的潜于增加遭到美国安全及商业壁垒的制约,这些壁垒拦阻了该公司于中国发卖其进步前辈芯片的能力。
黄仁勋假想,英伟达将继承于人工智能范畴阐扬主要作用,经由过程连续满意市场对于驱动谈天呆板人(如 OpenAI 的 ChatGPT 及google的 Gemini)的芯片的狂热需求,并扩展其于推理处置惩罚器新兴市场的影响力。
一旦人工智能东西颠末练习,推理芯片就能让这项技能应用所学到的常识并孕育发生相应——不管是编写文档还有是创立图象——其效率都比构建年夜型语言模子时利用的处置惩罚器更高。
英伟达首席履行官黄仁勋一直以来都传播鼓吹,2026年将是推理能力主导人工智能的一年。于3月4日的投资者年夜会上,他认可“咱们此刻看到的这类迁移转变点实在早已经显而易见,它素质上是人工智能利用文件、拜候文件及利用东西的能力。”
“推理迁移转变点已经经到来,”黄仁勋夸大。
英伟达今朝面对的挑战是,其脱销产物于推理计较方面的吸引力远不如于练习计较方面。用户反应,其Grace Blackwell办事器能耗巨年夜,且内存不足,没法让AI模子快速高效地回覆用户查询。
“英伟达此刻处境很难堪,”危害投资家、麻省理工学院数字经济规划研究员保罗·凯德罗斯基暗示。“很长一段时间以来,詹森一直说,‘咱们不需要专用的自力推理芯片,直接用Blackwell就好了。’但此刻环境已经经差别了,并且涌现出了许多新的竞争敌手。”
凯德罗斯基认为,英伟达近来一个季度的毛利率高达73%,但因为两个缘故原由,其毛利率一定会降落。起首,推理计较的贸易模式很是器重效率及降低终极产物的出产成本,而对于在消费者而言,终极产物指的是人工智能东西。其暗地里的硬件成本不克不及过高,不然不管是直接发卖还有是作为中间商发卖的公司都没法盈利。
其次,因为更多芯片公司找到了降低芯片采办及运营成本的要领,推理计较范畴的竞争也越发激烈。英伟达依附其硅芯片(相称在速率快、机能强、价格昂贵的法拉利跑车)成为首家市值4万亿美元的公司,但如今,世界需要的是普锐斯及特斯拉Model Y如许的“家用轿车”。
“所有这些推理方面的工具对于詹森来讲都*威逼,由于这一切都因此效率为导向的,”凯德罗斯基说。“他正冒死想措施将这个系列拓展到推理范畴。”
在是,为了帮忙其顺遂过渡到推理范畴,英伟达与市场专家 Groq 告竣了一项数十亿美元的授权和谈,此中包括聘任该草创公司的*工程师。
“英伟达不会将任何市场份额让给google或者Meta,”艾夫斯说道,他认为英伟达的市值将于将来一年摆布跨越6万亿美元。
GPU再也不是*主角
此外,还有有其他迹象注解,英伟达正于将其重心从GPU转向推理计较解决方案提供商。本年2月,Meta Platforms公布将于其人工智能数据中央部署数千颗英伟达Vera CPU,这是英伟达人工智能体系初次年夜范围部署,且未利用GPU。人们愈来愈熟悉到,推理计较可使用CPU完成,其实不必然需要英伟达的旗舰芯片。
据《华尔街日报》报导,英伟达也规划推出新的计较解决方案,该方案将采用多个自力在GPU的CPU,近似在Meta的规划。英特尔也规划推出近似解决方案。
趁便提一下,英特尔今天于圣何塞进行的Nvidia GTC 2026 年夜会上公布,其 Xeon 6 处置惩罚器将作为 Nvidia DGX Rubin NVL8 体系的主机 CPU,从而扩大了两家公司此前于基在 DGX B300 Blackwell 的平台上利用Xeon 6776P成立的 x86 互助瓜葛。
DGX Rubin NVL8 是英伟达的下一代旗舰级 AI 办事器体系。于该配置中,主机 CPU 卖力使命编排、内存治理、调理以和向 GPU 加快器传输数据。跟着推理事情负载向智能体 AI 及推理体系改变,这些功效对于单核机能及内存带宽的要求愈来愈高。
回到GTC主题演讲,黄仁勋将英伟达描写为“垂直整合但横向开放”,这也许会引起美国联邦商业委员会的存眷。不管怎样,英伟达暗示,鉴在其于加快计较范畴的方针——向客户提供完备的技能栈——“别无他法”。与此同时,他还有将英伟达描写为“垂直整合但横向开放”,这也许会引起美国联邦商业委员会的存眷。不管怎样,英伟达暗示,鉴在其于加快计较范畴的方针——向客户提供完备的技能栈——“别无他法”。
于此次年夜会上,黄仁勋再次预报了下一代Feynman体系。该体系配备了全新的GPU、LPU、名为Rosa的全新CPU、Bluefield 5以和Kyber架构,并撑持铜缆及CPO扩大。Feynman体系估计将在2028年发布。

于推理迅速突起确当下,英伟达可否继承垄断市场,咱们边走边看,但黄仁勋以和英伟达必定布满决定信念。
由于正如他所说,“摩尔定律已经经掉去了动力,加快计较让咱们可以或许取患上巨年夜的奔腾。”
【本文由投资界互助伙伴微信公家号:半导体行业不雅察授权发布,本平台仅提供信息存储办事。】若有任何疑难,请接洽(editor@zero2ipo.com.cn)投资界处置惩罚。
-304永利集团官网入口



