
304永利集团官网入口-黄仁勋又让整个硅谷睡不着了
首页财产阐发评论ai正文 黄仁勋又让整个硅谷睡不着了 凌晨2点于圣何塞SAP中央,黄仁勋演讲抛出多“炸弹”,如Vera Rubin平台等,还有说起英伟达至少1万亿美元需求定单和AI工场贸易模式等。 2026-03-17 08:21 ·微信公家号:半导体财产纵横九林 AI投资人解读· 英伟达发布Vera Rubin平台,七款芯片协同组成强盛AI超等计较机,Vera CPU机能优胜,收购Groq团队后LPU带来新冲破,还有展示了全新收集与存储架构和太空计较办事。黄仁勋称英伟达看到2027年至少1万亿美元需求定单,先容了AI工场中Token分层订价系统。此外,英伟达撑持OpenClaw并推出NemoClaw保障安全。 · 行业竞争激烈,其他芯片厂商可能推出近似产物抢占市场;技能更新换代快,若英伟达不克不及连续立异,可能面对被裁减危害。 总结:英伟达依附强盛的芯片技能及立异的贸易模式揭示出巨年夜投资潜力,但需存眷竞争与技能更新危害,建议深切研究其技能上风、市场需求和竞争格式后再做投资决议计划。内容由AI天生,仅供参考
圣何塞SAP中央,凌晨2点。黄仁勋再次穿戴那件好像永远不会旧的黑皮衣走上台。这场长达2小时的演讲中,老黄扔出了狂扔“核弹”。
*颗炸弹:Vera Rubin平台。七款全新芯片周全投产,Vera Rubin平台由七款冲破性芯片、五个机架及一个巨型超等计较机构成。同时发布Vera CPU,效率是传统机架势CPU的两倍,速率晋升50%。
第二颗炸弹:1万亿美元。黄仁勋于台上公布,英伟达今朝看到了至少1万亿美元的需求定单,笼罩到2027年。
第三颗炸弹:Token成为商品。“Token是新的商品。”黄仁勋公然具体论述了AI工场的贸易模式——Token的分层订价系统,从免费层到premium层。
第四颗炸弹:为OpenClaw社区发布 NemoClaw。这款开源项目“于几周内就做到了linux 30年才做到的事”,黄仁勋断言:“每一一家公司都需要OpenClaw战略。”
这场发布会留下了太多需要消化的信息。芯片、工场、呆板人、AI Agent......每个词均可能是下一个万亿市场的进口。假如你今晚错过了这场直播,这篇文章会告诉你黄仁勋到底说了甚么。
0一、
芯片核兵器库
Vera Rubin来了。
Vera Rubin是英伟达为“代办署理式AI”(Agentic AI)专门设计的新一代计较平台。
与上一代Blackwell 平台比拟,Vera Rubin揭示了惊人的效能跃进。该体系仅需1/4的GPU 便可完成混淆专家年夜模子(MoE)的练习,且每一瓦推论吞吐量飙升高达10 倍,乐成将单Token的天生成本降至十分之一。于基础举措措施配置上,新一代的NVL72机架经由过程第六代NVLink毗连了72块Rubin GPU与36块Vera CPU。黄仁勋尤其指出,第六代NVLink互换体系是极端难以实现的技能,但英伟告竣功告竣了这项创举。

此外,Vera Rubin体系采用100%液冷设计,利用45°C的温水举行冷却,完全移除了了传统复杂的缆线。这不仅年夜幅减轻了数据中央的冷却压力与能源成本,更将已往需要破费两天才能完成的安装时间,惊人地缩短至仅需两小时。
该平台整合了Vera CPU、Rubin GPU、NVLink 6 互换机、ConnectX - 9 超等网卡、BlueField - 4 DPU及Spectrum-6 以太网互换机,以和新集成的Groq 3 LPU。这些芯片协同事情,组成一台强盛的AI 超等计较机,为 AI 的各个阶段提供撑持——从年夜范围预练习、后练习及测试时扩大,到及时智能推理。
黄仁勋暗示:“Vera Rubin 是一次代际奔腾——它由七款冲破性芯片、五个机架及一个巨型超等计较机构成,旨于为人工智能的各个阶段提供强盛撑持。”
Vera CPU强势登场
本次年夜会的一年夜亮点,是英伟达首度揭示其于中心处置惩罚器(CPU)范畴的强盛野心。英伟达最初在2022年GTC年夜会上发布了*代Grace CPU,今晚老黄正式发布了Vera CPU及Vera CPU机架,标记着英伟达正式进军CPU直销范畴,成为传统CPU市场中英特尔及AMD的有力竞争敌手。
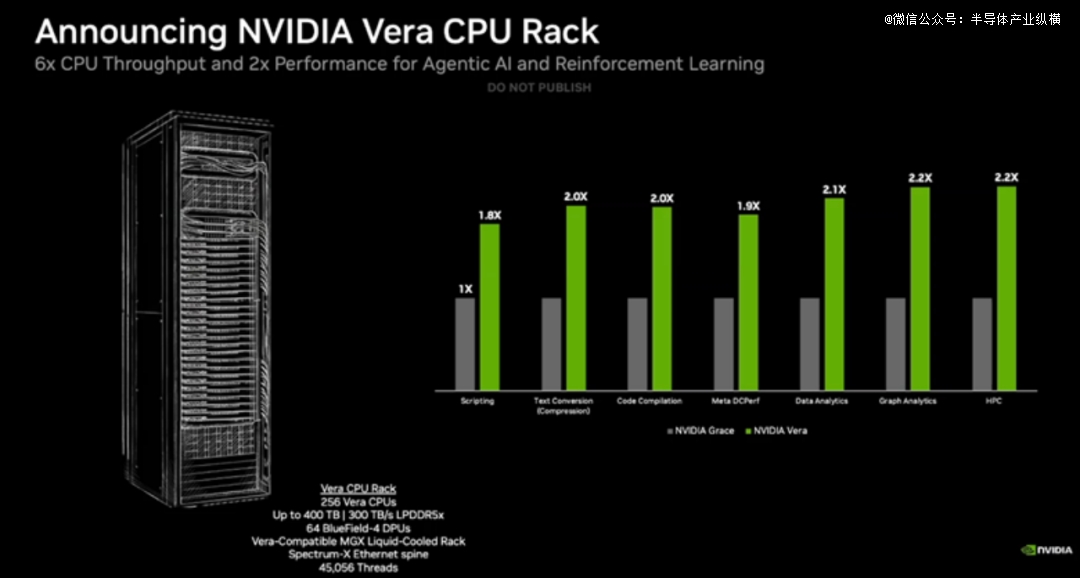
Vera CPU的定位是年夜范围数据处置惩罚、AI 练习及智能体推理场景,其效率是传统机架势CPU 的两倍,速率晋升50%。
为了应答AI利用东西时所需的极速反映,Vera CPU专为极高的单线程效能、强盛的资料处置惩罚能力与*的能源效率而设计。单颗Vera芯片配备了88个焦点与144个线程,采用英伟达深度定制化的Arm v9.2-A Olympus焦点,其指令级平行度(IPC)实现了1.5倍的代际晋升。
更具革命性的是,该架构首发引入了"空间多线程(Spatial Multithreading)"黑科技,经由过程实体断绝流水线组件,让多个线程能真正于单核上同时运行,完全消弭了传统多线程技能因资源列队而酿成的算力损耗。Vera CPU也是全世界*采用LPDDR5的数据中央CPU,提供*的单线程效能与每一瓦效能。
作为NVIDIA Vera Rubin NVL72平台的一部门,Vera CPU经由过程NVLink-C2C互连技能与GPU配对于,提供1.8 TB/s的相关带宽(是PCIe Gen 6带宽的7倍),实现CPU及GPU之间的高速数据同享。
英伟达暗示,阿里巴巴、CoreWeave、Meta及Oracle云基础举措措施,以和戴尔科技、HPE、遐想、超微等全世界体系制造商都与NVIDIA互助部署Vera。同时,英伟达发布了Vera CPU机架,提供基在NVIDIA MGX的密集型液冷基础举措措施,集成256个Vera CPU,可提供可扩大、节能的容量以和世界一流的单线程机能,从而年夜范围开释智能AI的潜力。
Vera CPU今朝已经周全投产,估计将在本年下半年最先交付。
收购Groq后,LPU登场
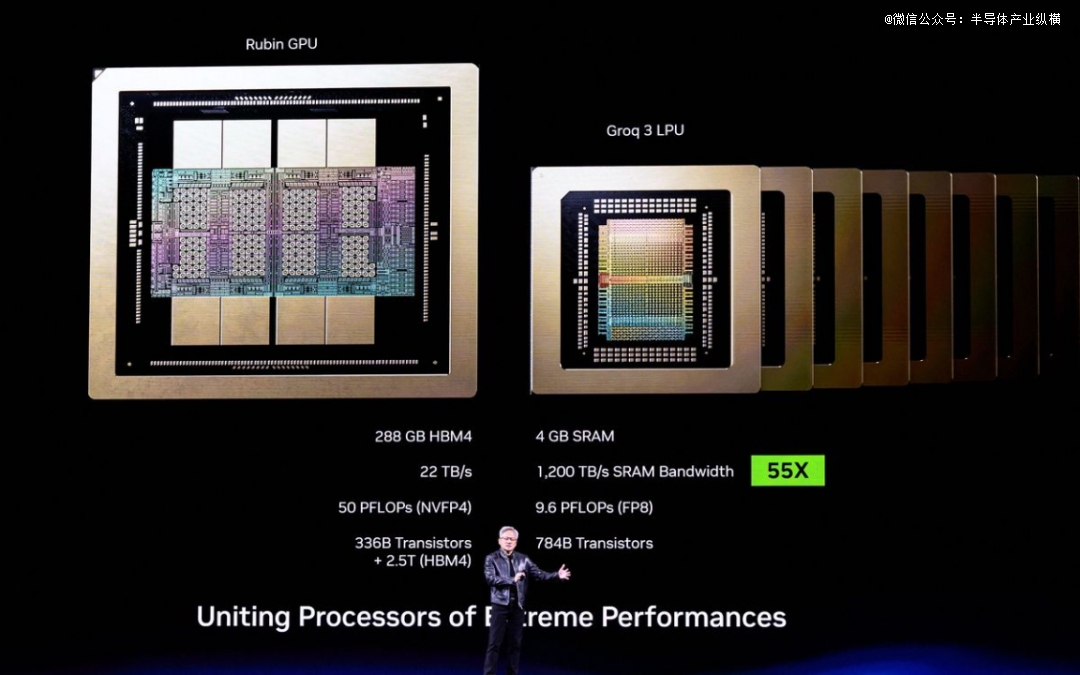
英伟达收购了开发Groq芯片的团队,并将其技能与Vera Rubin深度整合。
为何需要LPU?
与年夜大都依靠HBM作为事情内存层的AI加快器差别,Groq 3 LPU每一个芯片都集成为了500MB的SRAM。这类内存也用在CPU及GPU的超高速缓存。虽然与每一个Rubin GPU上容量高达288GB的HBM4比拟,这显患上眇乎小哉,但这块SRAM可提供150 TB/s的带宽,远高在HBM的22 TB/s。对于在带宽敏感型AI解码操作而言,Groq 3芯片带宽的年夜幅晋升为推理运用带来了诱人的上风。
两种处置惩罚器的同一:LPU + Vera Rubin。“咱们想出了一个绝妙的主张,”黄仁勋注释道,“咱们将推理历程彻底从头架构。咱们把合适Vera Rubin的事情放于Vera Rubin上,然后把解码天生、低延迟、带宽受限的部门卸载到LPU上。”
这两种极度处置惩罚器的同一:一个为高吞吐量,一个为低延迟,孕育发生了使人震动的效果:每一兆瓦功耗的推理吞吐量最高可晋升35倍,万亿参数模子的收益时机最高可晋升10倍。
“35倍,”黄仁勋反复了一遍,“这是世界从未见过的。”
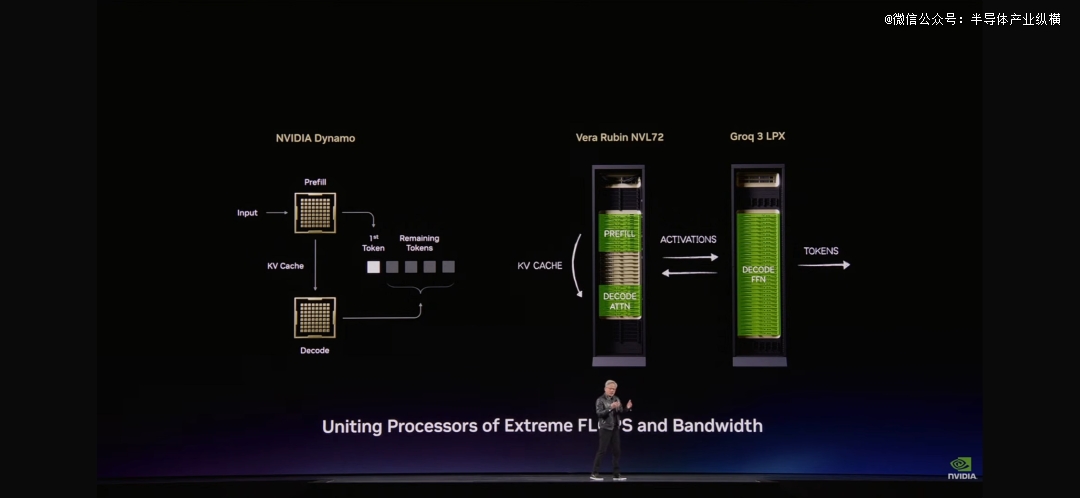

英伟达构建了包罗256个Groq 3 LPU的Groq 3 LPX机架。该机架提供128GB的SRAM及40 PB/s的推理加快带宽,并经由过程每一个机架640 TB/s的专用扩大接口将这些芯片毗连起来。
年夜范围部署时,LPU 集群可作为一个巨型单处置惩罚器,实现快速、确定性的推理加快。与Vera Rubin NVL72 集成,Rubin GPU 及 LPU 经由过程结合计较每一个输出标志的 AI 模子每一一层,显著晋升解码速率。
LPX采用全液冷设计,基在MGX基础举措措施构建,可无缝集成到将在本年下半年推出的下一代Vera Rubin AI工场中。
重塑收集与AI 原保存储架构
于收集毗连与集群扩大方面,英伟达展示了全新一代的Kyber机架,这是一款专为Rubin Ultra 运算节点设计的体系。有别在传统的程度插拔,Kyber 采用垂直插入设计,经由过程违板的中板(Midplane)毗连,乐成于单一NVLink 网域内毗连多达144 个GPU,冲破了传统铜缆毗连的间隔限定。
同时,英伟达也与台积电互助,*量产名为COUPE的革命性配合封装光学(CPO)技能,并运用在全世界*CPO Spectrum-X 互换器中,让光学旌旗灯号直接与芯片对于接。
英伟达从头设计了整个存储体系:BlueField - 4 STX 存储机架。可将 GPU 内存无缝扩大到整个 POD(物理数据中央)。STX 由 BlueField-4 提供撑持,BlueField-4 联合了Vera CPU及ConnectX-9 SuperNIC,可提供高带宽同享层,该层针对于存储及检索年夜型语言模子及智能 AI 事情流天生的海量键值缓存数据举行了优化。
太空计较也来了

于GTC年夜会上,老黄还有发布了NVIDIA Space-1 Vera Rubin模块,标记着英伟达正式推出太空计较办事。与NVIDIA H100 GPU比拟,该模块上的Rubin GPU可为基在太空的推理提供高达25倍的AI计较能力,从而为ODC(漫衍式计较中央)、高级地舆空间智能处置惩罚及自立太空操作提供下一代计较能力。
按照英伟达官方新闻稿,Vera Rubin 空间模块专为于太空直接运行 LLM 及高级基础模子的轨道数据中央而设计,它采用慎密集成的CPU-GPU 架谈判高带宽互连,旨于及时处置惩罚来自太空仪器的年夜量数据流。
黄仁勋说到:“太空计较,这片末了的边境,已经经到来。跟着咱们部署卫星星座并深切摸索太空,智能必需存于在数据孕育发生的任何处所。”

这场发布会还有展示了完备的芯片线路图。“每一年一个全新架构,”黄仁勋总结道,“这就是英伟达的速率。”
02
1万亿美元:英伟达看到的需求
“5000亿美元。”这是去年GTC年夜会上,黄仁勋宣布的英伟达看到的高置信度需乞降采购定单。
其时他认为这个数字已经经很是惊人。“但此刻,一年已往了,就于我此刻站的位置,我看到了至少1万亿美元的需求,笼罩到2027年。”
为何需求会这么年夜?“由于推理的迁移转变点已经经到来。”黄仁勋于演讲中具体注释了缘故原由。
已往两年发生了甚么?“三件工作。”黄仁勋回首道。*,ChatGPT开启了天生AI时代。“它不只是理解及感知,还有能翻译及天生怪异的内容。”第二,推理AI(o1/o3)呈现了。“它能反思,能思索,能计划,能把一个没法理解的问题分化成能理解的步调。这让ChatGPT真正腾飞了。”第三,claude code呈现了:*个代办署理式模子。“它能读文件、写代码、编译、测试、评估、迭代。claude code完全转变了软件工程。”
黄仁勋说了一个要害数据:"已往两年,AI的计较需求增长了约莫1万倍。AI此刻必需思索。为了思索、为了履行、为了浏览,它都必需推理。每一一次交互,它都于推理。已往的练习时代已经颠末去了。此刻是推理的时代。”这就是1万亿美元需求的来历。每个公司都于设置装备摆设AI工场,每个工场都需要Token出产。
Token是新的商品
“Token是新的商品。”当黄仁勋于GTC 2026上说出这句话时,整个AI行业的贸易模式正于被从头界说。于黄仁勋展示的那张“最主要的图表”上,横轴是Token速度,纵轴是吞吐量。这张图表将决议将来每个CEO的决议计划——由于它直接瓜葛到AI工场的营收。
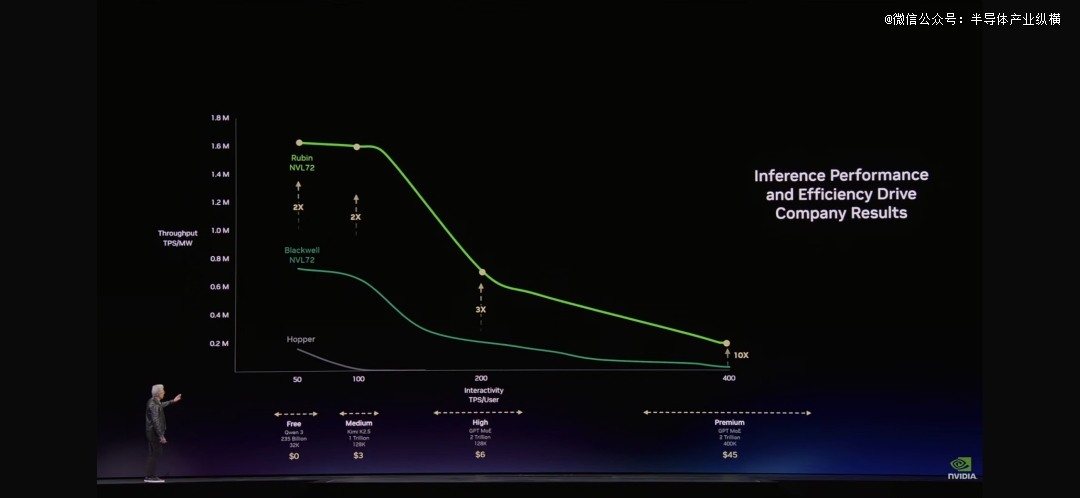
黄仁勋具体注释了AI工场的贸易模式,此中提到了Token的分层订价:
免费层:高吞吐量、低速率——用在吸援用户
*层:中等速率——美金3/百万Token
第二层:高速率、长上下文——美金45/百万Token
premium层:超高速率——美金150/百万Token
“就像任何行业同样,"黄仁勋注释道,"更高的质量,更高的机能,更低的容量。Grace Blackwell于你的免费层晋升了巨年夜吞吐量,但于你最能变现的层级,它晋升了35倍。Vera Rubin又于这个基础上晋升了10倍。
“假定你用25%的电力于免费层,25%于中等层,25%于高层层,25%于premium层。你的数据中央只有1吉瓦。你需要决议怎样分配。”黄仁勋算了一笔账:免费层吸援用户,premium层办事最有价值的客户。这类组合,根据这张图表计较——Blackwell可以孕育发生5倍的营收,Vera Rubin又是5倍。
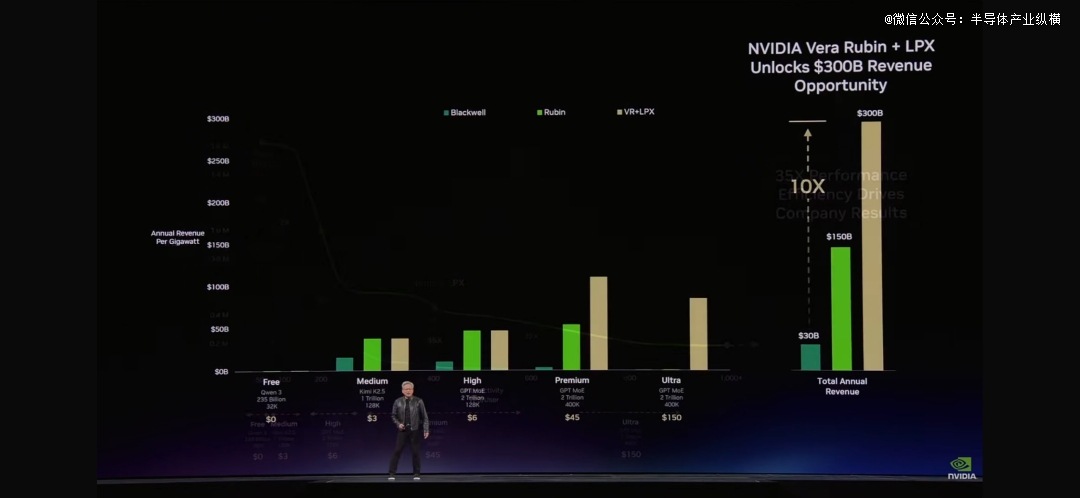
"你应该于Vera Rubin上尽快步履,"黄仁勋建议道,"由于你的Token成本会降落,吞吐量会上升。"
"于两年时间内,于一个1吉瓦的工场中,利用我以前展示的数学,摩尔定律只能给咱们带来几个步调的晋升。但有了这个架构,咱们的Token天生速度将从2200万晋升到7亿——晋升350倍。"这就是“*协同设计”的气力。黄仁勋称之为“垂直整合然后程度开放”的计谋。
03
黄仁勋夸赞龙虾
"OpenClaw是人类汗青上*的开源项目。它于几周内就做到了Linux 30年才做到的事。"
当黄仁勋公布英伟达撑持OpenClaw时,全场再次沸腾。OpenClaw是一个Agentic体系(代办署理式体系)的操作体系。它毗连年夜型语言模子,治理资源,拜候东西及文件体系,履行调理,创立子代办署理,这些能力让它险些就是一个完备的操作体系。
“于OpenClaw呈现以前,小我私家电脑由于Windows而成为可能,“黄仁勋说道,”此刻,OpenClaw让创立小我私家Agent成为可能。其寄义是深远的。”
Agentic体系可以拜候敏感信息、履行代码、与外部通讯,这带来了巨年夜的安全挑战。英伟达推出了NemoClaw,利用NVIDIA Agent Toolkit软件,只需一条号令便可优化 OpenClaw。它安装OpenShell,提供开放模子及断绝的沙箱,为自立代办署理增长数据隐私及安全保障。
04
结语
从一块GPU到一座AI工场,黄仁勋用十年时间完成为了英伟达的进化。GTC 2026的年夜幕已经经拉开。看完这场发布会,你最体贴的问题是甚么?
你感觉英伟达的下一个十年会被"神化"还有是"拉下神坛"?
【本文由投资界互助伙伴微信公家号:半导体财产纵横授权发布,本平台仅提供信息存储办事。】若有任何疑难,请接洽(editor@zero2ipo.com.cn)投资界处置惩罚。
-304永利集团官网入口



